
11:10 p.m.
Please yr help with this issue
After performing a simple Linear regression (file attached) and asking for
a Breush Pagan Heterocedasticity test in Menu TEST I get the response below
[image: image.png]
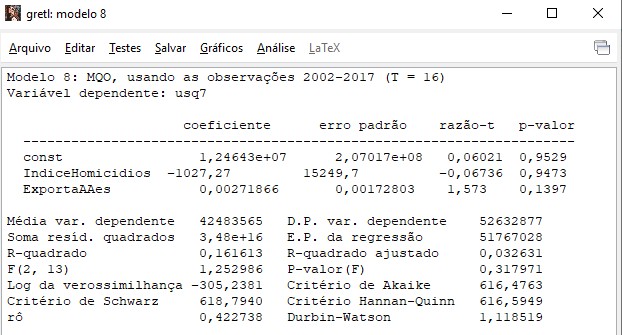
Instead if square residual are saved and used as a Dependent variable
against above regressors the answer is different, please see below
[image: image.png]
Why does it happen?
please, I am waiting for your Help and advise
best regrards
{kind=link}
{kind=link}

1:03 p.m.
On Sat, 13 Jun 2020, Salvatore Salvo wrote:
Please yr help with this issue
After performing a simple Linear regression (file attached) and asking for
a Breush Pagan Heterocedasticity test in Menu TEST I get the response below
Instead if square residual are saved and used as a Dependent variable
against above regressors the answer is different, please see below
Why does it happen?
In the Breusch-Pagan test (T. S. Breusch and A. R. Pagan,
Econometrica 47/5, 1979), the dependent variable in the auxiliary
regression is the squared residual scaled by the ML estimate of its
variance:
series g = $uhat^2 / ($ess/$T)
Regress this on the relevant regressors and you will reproduce
gretl's test. The LM test statistic is half of the Regression (or
"Explained") sum of squares. After running the auxiliary regression
you can find it as
LM = (sst(g) - $ess) / 2
Here's a complete example:
open data4-10
ols ENROLL 0 CATHOL INCOME
modtest --breusch-pagan
series g = $uhat^2 / ($ess/$T)
ols g 0 CATHOL INCOME --simple-print
LM = (sst(g) - $ess) / 2
Allin Cottrell
2:48 a.m.
OK, this is more interesting than I thought (and I'd welcome
comments/criticism from others).
Salvatore's question is prompted by a difference in results between
gretl's Breusch-Pagan test for heteroskedasticity (via the command
modtest --breusch-pagan) and the test as implemented in Eviews.
First point: on the face of it there's a difference between the test
actually proposed by Breusch and Pagan (Econometrica, 1979), which
I'll call Test1, and that performed in Eviews, which I'll call
Test2. (Eviews is by no means alone in using Test2, it's also the
one described in the Wikipedia entry.) Both tests involve auxiliary
regressions estimated via OLS, with the same set of independent
variables, but
* In Test1 the dependent variable is the squared residual from the
original regression divided by the ML estimator of the error
variance for that regression, and the LM test statistic is half of
the explained sum of squares from the auxiliary regression. (This is
very clearly set out on the first page of the B-P paper.)
* In Test2 the dependent variable is the (unscaled) squared residual
from the original regression and the LM test statistic is sample
size times R^2 from the auxiliary regression.
At first I thought this difference might be merely apparent (that
is, the results should be numerically identical if done right). But
I couldn't prove that and (unless I've messed up) simulation shows
that they're not at all numerically identical. (Maybe they're
asymptotically equivalent?) In that case, which one is "right" or
"better"?
Monte Carlo to the rescue. I show my test script below. It can be
run in two modes, depending on the value of "H0_true" near the top
of the script.
* If H0_true = 1 the simulated error is homoskedastic and the
rejection rates for the two tests give a measure of their sizes. I'm
using the 5 percent significance level, so ideally the empirical
rejection rate should be close to 0.05.
* If H0_true = 0 the simulated error is by construction
heteroskedastic and the rejection rates give a measure of power.
On running the script in both modes several times, here's what I
see:
* Size: both tests seem about right. Sometimes one is closer to the
nominal size of 0.05, sometimes the other.
* Power: Test1 (the original) seems to be substantially better.
Here are rejection rates from a few runs:
H0_true = 1
Test1 0.049, Test2 0.053
Test1 0.043, Test2 0.046
Test1 0.048, Test2 0.047
H0_true = 0
Test1 0.548, Test2 0.311
Test1 0.546, Test2 0.316
Test1 0.698, Test2 0.520
If anyone sees an error in my simulation, please let me know!
<hansl>
set verbose off
# sample size for regressions
nulldata 100
# uncomment below for reproducible results
# set seed 76543
# error term is homoskedastic?
H0_true = 1
# independent variable
series x = normal()
# 5 percent critical value for chi-square(1)
scalar X1crit = critical(X, 1, 0.05)
# number of replications
K = 5000
# recorders
matrix reject = zeros(1,2)
matrix LMdiff = zeros(K,1)
loop i=1..K --quiet
e = normal()
if H0_true
# homoskedastic
y = 10 + x + e
else
# heteroskedastic
y = 10 + x + 0.2*x*e
endif
# estimate original regression
ols y 0 x --quiet
u2 = $uhat^2
# Test1: as Breusch and Pagan (1979)
vml = $ess / $T
g = u2/vml
ols g 0 x --quiet
LM1 = (sst(g) - $ess)/2
reject[1] += LM1 > X1crit
# Test2: as Wikipedia, Eviews
ols u2 0 x --quiet
LM2 = $trsq
reject[2] += LM2 > X1crit
LMdiff[i] = LM1 - LM2
endloop
reject /= K
printf "Rejection rates at 5 percent level:\n"
printf " Test1 %.3f, Test2 %.3f\n", reject[1], reject[2]
colnames(LMdiff, "LMdiff")
summary --matrix=LMdiff --simple
</hansl>
Allin

8:46 a.m.
Am 14.06.2020 um 17:48 schrieb Allin Cottrell:
OK, this is more interesting than I thought (and I'd welcome
comments/criticism from others).
Salvatore's question is prompted by a difference in results between
gretl's Breusch-Pagan test for heteroskedasticity (via the command
modtest --breusch-pagan) and the test as implemented in Eviews.
First point: on the face of it there's a difference between the test
actually proposed by Breusch and Pagan (Econometrica, 1979), which I'll
call Test1, and that performed in Eviews, which I'll call Test2.
This old thread from the Stata forum might be relevant:
https://www.stata.com/statalist/archive/2006-04/msg00076.html
So maybe power turns around for non-Gaussian scenarios.
cheers
sven
12:44 p.m.
On Sun, 14 Jun 2020, Sven Schreiber wrote:
Am 14.06.2020 um 17:48 schrieb Allin Cottrell:
> OK, this is more interesting than I thought (and I'd welcome
> comments/criticism from others).
>
> Salvatore's question is prompted by a difference in results between
> gretl's Breusch-Pagan test for heteroskedasticity (via the command
> modtest --breusch-pagan) and the test as implemented in Eviews.
>
> First point: on the face of it there's a difference between the test
> actually proposed by Breusch and Pagan (Econometrica, 1979), which I'll
> call Test1, and that performed in Eviews, which I'll call Test2.
This old thread from the Stata forum might be relevant:
https://www.stata.com/statalist/archive/2006-04/msg00076.html
So maybe power turns around for non-Gaussian scenarios.
Certainly relevant; thanks, Sven. I hadn't twigged that "Test2" is
equivalent to Koenker's robust B-P version. I re-ran my test script
with uniform errors (should probably try some other cases) and
found:
* Under H0 the original B-P test is "under-sized": rejects at much
less than 5 percent frequency using alpha = 0.05. The size of the
robust version is roughly right.
* Under my H1, error=0.2*x*uniform(), the original B-P test still
rejects with much higher frequency than the Koenker variant.
Allin
5:07 a.m.
Am 15.06.2020 um 03:44 schrieb Allin Cottrell:
On Sun, 14 Jun 2020, Sven Schreiber wrote:
> So maybe power turns around for non-Gaussian scenarios.
Certainly relevant; thanks, Sven. I hadn't twigged that "Test2" is
equivalent to Koenker's robust B-P version. I re-ran my test script with
uniform errors (should probably try some other cases) and found:
* Under H0 the original B-P test is "under-sized": rejects at much less
than 5 percent frequency using alpha = 0.05. The size of the robust
version is roughly right.
* Under my H1, error=0.2*x*uniform(), the original B-P test still
rejects with much higher frequency than the Koenker variant.
Obviously, if the original test were always correctly sized or
conservative _and_ had more power, it would be superior. My suspicion is
that for other kinds of violations of the assumptions it might be
oversized, however. But I don't know this specific literature, so far as
it exists.
cheers
sven
5:22 a.m.
On Mon, 15 Jun 2020, Sven Schreiber wrote:
Am 15.06.2020 um 03:44 schrieb Allin Cottrell:
> On Sun, 14 Jun 2020, Sven Schreiber wrote:
>> So maybe power turns around for non-Gaussian scenarios.
>
> Certainly relevant; thanks, Sven. I hadn't twigged that "Test2" is
> equivalent to Koenker's robust B-P version. I re-ran my test script with
> uniform errors (should probably try some other cases) and found:
>
> * Under H0 the original B-P test is "under-sized": rejects at much less
> than 5 percent frequency using alpha = 0.05. The size of the robust
> version is roughly right.
>
> * Under my H1, error=0.2*x*uniform(), the original B-P test still
> rejects with much higher frequency than the Koenker variant.
Obviously, if the original test were always correctly sized or
conservative _and_ had more power, it would be superior. My suspicion is
that for other kinds of violations of the assumptions it might be
oversized, however. But I don't know this specific literature, so far as
it exists.
I tried another run of my Monte Carlo, with t(12) errors. Original
B-P was somewhat oversized (around 0.075 or 0.08 for nominal 0.05)
but reasonably powerful. The Koenker robust variant was correctly
sized at 0.05 (as claimed) but had about 1/2 to 5/8 the power
against my H1 (with error multiplied by 0.2*x).
It seems the subsequent literature has kind of skated over Koenker's
1981 caveat, that the statistic is "not entirely satisfactory" since
"the power of the resulting test may be quite poor except under
idealized Gaussian conditions". I would add, _even_ under Gaussian
conditions.
Allin
8:34 a.m.
Am 15.06.2020 um 20:22 schrieb Allin Cottrell
I tried another run of my Monte Carlo, with t(12) errors. Original
B-P
was somewhat oversized (around 0.075 or 0.08 for nominal 0.05) but
reasonably powerful. The Koenker robust variant was correctly sized at
0.05 (as claimed) but had about 1/2 to 5/8 the power against my H1 (with
error multiplied by 0.2*x).
Well if you size-adjust the first test by multiplying with 0.05/0.08 you
also arrive at 5/8 of the raw power. So maybe not so different.
It seems the subsequent literature has kind of skated over
Koenker's
1981 caveat, that the statistic is "not entirely satisfactory" since
"the power of the resulting test may be quite poor except under
idealized Gaussian conditions". I would add, _even_ under Gaussian
conditions.
So what about Wooldridge's F version? It uses the same auxiliary
regression as Koenker and simply takes the ordinary F statistic from
that. Although I fail to see why that would have more power, but who knows.
cheers
sven
2221
days inactive
2223
days old
7 comments
3 participants
participants (3)
-
 Allin Cottrell
Allin Cottrell -
 Salvatore Salvo
Salvatore Salvo -
 Sven Schreiber
Sven Schreiber