
6:58 a.m.
Hi,
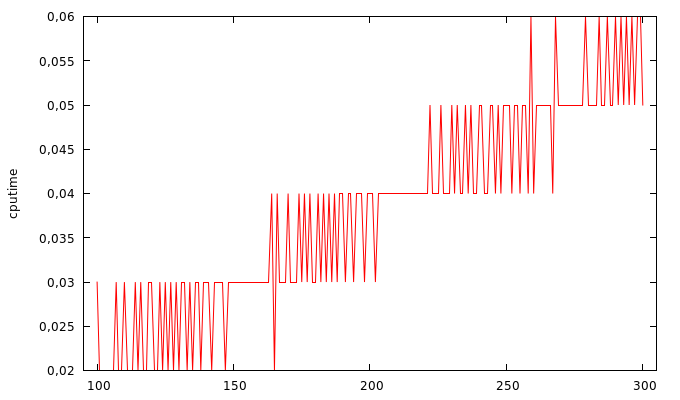
I'm benchmarking the Mahalanobis distance to see how the accuracy and
execution time changes with an increasing sample size. As far as I
understand the algorithm the execution time should grow linearly as the
sample size increases. The weird thing is that the time grows linearly up
to (and including) 199 samples, but then suddenly has a drop at 200
samples. I've attached a graph to illustrate this.
I'm using it to do outlier detection. The time drops at 200 samples, but
the accuracy increases without a sudden drop.
Does anyone know why this happens?
Chris
{kind=link}

9:15 a.m.
On Tue, 15 Apr 2014, GOO Creations wrote:
Hi,
I'm benchmarking the Mahalanobis distance to see how the accuracy and
execution time changes with an increasing sample size. As far as I
understand the algorithm the execution time should grow linearly as the
sample size increases. The weird thing is that the time grows linearly up
to (and including) 199 samples, but then suddenly has a drop at 200
samples. I've attached a graph to illustrate this.
I'm using it to do outlier detection. The time drops at 200 samples, but
the accuracy increases without a sudden drop.
Weird. I'm not seeing this here, and I have no clue as to why what you're
seeing should happen.
Are you using a C program + libgretl or one of the gretl clients?
Could you try to run this on your system (via the CLI or the GUI) and see
what happens?
<hansl>
set echo off
set messages off
nulldata 300
setobs 1 1 --special-time-series
set seed 15042014
k = 20
list X = null
loop i = 1..k --quiet
series x_$i = normal()
list X += x_$i
endloop
series cputime = NA
loop t = 100 .. $nobs --quiet
smpl 1 t
set stopwatch
loop 100
mahal X --quiet
endloop
cputime[t] = $stopwatch
endloop
gnuplot cputime time --with-lines --output=display
</hansl>
-------------------------------------------------------
Riccardo (Jack) Lucchetti
Dipartimento di Scienze Economiche e Sociali (DiSES)
Università Politecnica delle Marche
(formerly known as Università di Ancona)
r.lucchetti(a)univpm.it
http://www2.econ.univpm.it/servizi/hpp/lucchetti
-------------------------------------------------------

11:25 a.m.
On Tue, 15 Apr 2014, GOO Creations wrote:
I'm benchmarking the Mahalanobis distance to see how the accuracy
and
execution time changes with an increasing sample size. As far as I
understand the algorithm the execution time should grow linearly as the
sample size increases. The weird thing is that the time grows linearly up
to (and including) 199 samples, but then suddenly has a drop at 200
samples. I've attached a graph to illustrate this.
What implementation of lapack/blas are you using?
The most demanding task in computing Mahalanobis distance is the inversion
of the covariance matrix of the selected series, which is performed via
the lapack Cholesky functions dpotrf and dpotri. Depending on the
implementation, these functions may switch algorithm based on the size of
the input data (e.g. invoking parallelization when a certain threshold
size is exceeded).
Allin Cottrell
11:41 a.m.
On Tue, 15 Apr 2014, Allin Cottrell wrote:
On Tue, 15 Apr 2014, GOO Creations wrote:
> I'm benchmarking the Mahalanobis distance to see how the accuracy and
> execution time changes with an increasing sample size. As far as I
> understand the algorithm the execution time should grow linearly as the
> sample size increases. The weird thing is that the time grows linearly up
> to (and including) 199 samples, but then suddenly has a drop at 200
> samples. I've attached a graph to illustrate this.
What implementation of lapack/blas are you using?
The most demanding task in computing Mahalanobis distance is the inversion
of the covariance matrix of the selected series, which is performed via
the lapack Cholesky functions dpotrf and dpotri. Depending on the
implementation, these functions may switch algorithm based on the size of
the input data (e.g. invoking parallelization when a certain threshold
size is exceeded).
That's what I had thought too, initially. However, the size of the
covariance matrix doesn't depend on the number of observations, which is
the variable our friend is tracking (unless I misunderstood his message).
-------------------------------------------------------
Riccardo (Jack) Lucchetti
Dipartimento di Scienze Economiche e Sociali (DiSES)
Università Politecnica delle Marche
(formerly known as Università di Ancona)
r.lucchetti(a)univpm.it
http://www2.econ.univpm.it/servizi/hpp/lucchetti
-------------------------------------------------------
12:01 p.m.
On Tue, 15 Apr 2014, Riccardo (Jack) Lucchetti wrote:
On Tue, 15 Apr 2014, Allin Cottrell wrote:
> On Tue, 15 Apr 2014, GOO Creations wrote:
>
>> I'm benchmarking the Mahalanobis distance to see how the accuracy and
>> execution time changes with an increasing sample size. As far as I
>> understand the algorithm the execution time should grow linearly as the
>> sample size increases. The weird thing is that the time grows linearly up
>> to (and including) 199 samples, but then suddenly has a drop at 200
>> samples. I've attached a graph to illustrate this.
>
> What implementation of lapack/blas are you using?
>
> The most demanding task in computing Mahalanobis distance is the inversion
> of the covariance matrix of the selected series, which is performed via
> the lapack Cholesky functions dpotrf and dpotri. Depending on the
> implementation, these functions may switch algorithm based on the size of
> the input data (e.g. invoking parallelization when a certain threshold
> size is exceeded).
That's what I had thought too, initially. However, the size of the covariance
matrix doesn't depend on the number of observations, which is the variable
our friend is tracking (unless I misunderstood his message).
Duh! You're right. Then I can't explain this either.
Allin
2:11 p.m.
Hi everyone,
Thanks for the replies. Sorry for the late response.
Jack: Yes, I'm tracking the number of observations. I'm actually not
using the gretl GUI at all, I'm directly using the libraries. I pretty
much tested how long it takes to execute:
/ MahalDist *distance = get_mahal_distances(gretlParameters,
gretlData, OPT_NONE, NULL, &error);//
/
where gretlData is a DATASET with /n/ number of observations (so this is
the amount that I increased from 1 - 250). FYI: My system monitor
indicates that the statement above only executes on a single thread.
I ran your script in a Linux Mint virtual machine (4 cores, 4GB RAM) and
got different results compared to Helio. I ran the script a couple of
times (see attachments) and although different, they show similar
characteristics. I'm not sure how Helio got the first result.
Looking at the script output, I don't think it's the best way to
benchmarking the execution time in this case.
I've used 8 different datasets with 30-40 million samples each. Every
single window over every single dataset gave the exact same time jump
between 199 and 200 observations.
What I've done is start a timer just before calling the
/get_mahal_distances/ function and then stopping the timer right after.
I've done this a total of about 300 million times and the graphs I sent
in my original post is the average over all these tests - so it should
be a quite accurate estimation.
I'm using these results for my thesis, and I somehow have to explain why
this happens (even if it's just a performance improvement like Allin
said). So if anyone else knows why, please let me know.
In any case, thanks for the help
Chris
On 2014/04/15 02:01 PM, Allin Cottrell wrote:
On Tue, 15 Apr 2014, Riccardo (Jack) Lucchetti wrote:
> On Tue, 15 Apr 2014, Allin Cottrell wrote:
>
>> On Tue, 15 Apr 2014, GOO Creations wrote:
>>
>>> I'm benchmarking the Mahalanobis distance to see how the accuracy and
>>> execution time changes with an increasing sample size. As far as I
>>> understand the algorithm the execution time should grow linearly as the
>>> sample size increases. The weird thing is that the time grows linearly up
>>> to (and including) 199 samples, but then suddenly has a drop at 200
>>> samples. I've attached a graph to illustrate this.
>> What implementation of lapack/blas are you using?
>>
>> The most demanding task in computing Mahalanobis distance is the inversion
>> of the covariance matrix of the selected series, which is performed via
>> the lapack Cholesky functions dpotrf and dpotri. Depending on the
>> implementation, these functions may switch algorithm based on the size of
>> the input data (e.g. invoking parallelization when a certain threshold
>> size is exceeded).
> That's what I had thought too, initially. However, the size of the covariance
> matrix doesn't depend on the number of observations, which is the variable
> our friend is tracking (unless I misunderstood his message).
Duh! You're right. Then I can't explain this either.
Allin
_______________________________________________
Gretl-users mailing list
Gretl-users(a)lists.wfu.edu
http://lists.wfu.edu/mailman/listinfo/gretl-users
{kind=link}
{kind=link}
{kind=link}
2:55 p.m.
On Tue, 15 Apr 2014, GOO Creations wrote:
I've used 8 different datasets with 30-40 million samples each.
Every single
window over every single dataset gave the exact same time jump between 199
and 200 observations.
Sorry, _now_ I'm officially confused. Could you please clarify what you
mean by "samples" and "observations"?
-------------------------------------------------------
Riccardo (Jack) Lucchetti
Dipartimento di Scienze Economiche e Sociali (DiSES)
Università Politecnica delle Marche
(formerly known as Università di Ancona)
r.lucchetti(a)univpm.it
http://www2.econ.univpm.it/servizi/hpp/lucchetti
-------------------------------------------------------
3:49 p.m.
Hi again,
Sorry about the confusion. I that sentence 1 sample = 1 observation.
What I've basically done is execute the code a couple million times
(since I'm working with music files) to make sure that the average
execution time is as accurate as possible.
So my original graph indicates the average time it took to execute the
code with 1 observation in the data set, then 2 observations , 3
observations, until 250 observations (with the jump occurring between
199 and 200 observations).
I've attached a small example program (with a makefile) that does the
test. I'm using gettimeofday, which will probably only work under Linux.
It might take a couple of seconds to execute. I would apprciate it if
someone could run it (sorry Allin, this is probably the wrong mailing
list again for posting C code), and verify that I'm not the only one
with this time-jump.
These are my outputs:
/197 number of observations: 784814//
//198 number of observations: 760379//
//199 number of observations: 759822//
//200 number of observations: 598327//
//201 number of observations: 602174//
//202 number of observations: 604390//
//203 number of observations: 607213//
/
Chris
On 2014/04/15 04:55 PM, Riccardo (Jack) Lucchetti wrote:
On Tue, 15 Apr 2014, GOO Creations wrote:
> I've used 8 different datasets with 30-40 million samples each. Every
> single window over every single dataset gave the exact same time jump
> between 199 and 200 observations.
Sorry, _now_ I'm officially confused. Could you please clarify what
you mean by "samples" and "observations"?
-------------------------------------------------------
Riccardo (Jack) Lucchetti
Dipartimento di Scienze Economiche e Sociali (DiSES)
Università Politecnica delle Marche
(formerly known as Università di Ancona)
r.lucchetti(a)univpm.it
http://www2.econ.univpm.it/servizi/hpp/lucchetti
-------------------------------------------------------
_______________________________________________
Gretl-users mailing list
Gretl-users(a)lists.wfu.edu
http://lists.wfu.edu/mailman/listinfo/gretl-users

10:51 a.m.
Hello,
These are my results:
On Fedora 19.0 x64 4 core
[helio@localhost temp]$ ./test
197 number of observations: 707623
198 number of observations: 675847
199 number of observations: 679392
200 number of observations: 557697
201 number of observations: 536804
202 number of observations: 578269
203 number of observations: 544649
[helio@localhost temp]$ ./test
197 number of observations: 777980
198 number of observations: 764587
199 number of observations: 770005
200 number of observations: 623716
201 number of observations: 627000
202 number of observations: 630206
203 number of observations: 634468
[helio@localhost temp]$ ./test
197 number of observations: 695839
198 number of observations: 678020
199 number of observations: 681358
200 number of observations: 534876
201 number of observations: 537547
202 number of observations: 539711
203 number of observations: 543831
[helio@localhost temp]$ ./test
197 number of observations: 709759
198 number of observations: 684160
199 number of observations: 685812
200 number of observations: 534485
201 number of observations: 537334
202 number of observations: 573589
203 number of observations: 543497
On OpenSUSE 13.1 x64 2 core
helio@linux-techno:~> ./test
197 number of observations: 1060657
198 number of observations: 1097359
199 number of observations: 1104009
200 number of observations: 867470
201 number of observations: 872487
202 number of observations: 874292
203 number of observations: 881876
helio@linux-techno:~> ./test
197 number of observations: 730982
198 number of observations: 732811
199 number of observations: 736721
200 number of observations: 579397
201 number of observations: 584108
202 number of observations: 584735
203 number of observations: 588359
helio@linux-techno:~> ./test
197 number of observations: 731426
198 number of observations: 738590
199 number of observations: 741741
200 number of observations: 583523
201 number of observations: 584833
202 number of observations: 588973
203 number of observations: 592129
helio@linux-techno:~> ./test
197 number of observations: 730169
198 number of observations: 732672
199 number of observations: 737452
200 number of observations: 579829
201 number of observations: 583927
202 number of observations: 584652
203 number of observations: 589383
As you can see the time-jump also happens here. Note the high 1st run times
on OpenSUSE.
On Tue, Apr 15, 2014 at 4:49 PM, GOO Creations <goocreations(a)gmail.com>wrote:
...
I've attached a small example program (with a makefile) that does the
test. I'm using gettimeofday, which will probably only work under Linux. It
might take a couple of seconds to execute. I would apprciate it if someone
could run it (sorry Allin, this is probably the wrong mailing list again
for posting C code), and verify that I'm not the only one with this
time-jump.
These are my outputs:
*197 number of observations: 784814*
*198 number of observations: 760379*
*199 number of observations: 759822*
*200 number of observations: 598327*
*201 number of observations: 602174*
*202 number of observations: 604390*
*203 number of observations: 607213*
Chris
10:55 a.m.
Thanks Helio. So it's not just me.
Since the mathematics behind Mahalanobis indicate a linear dependency
between the observation count and the execution time, I'm simply going
to ignore this time-jump.
Thanks for all the help.
Regards
Chris
On 2014/04/16 12:51 PM, Hélio Guilherme wrote:
Hello,
These are my results:
On Fedora 19.0 x64 4 core
[helio@localhost temp]$ ./test
197 number of observations: 707623
198 number of observations: 675847
199 number of observations: 679392
200 number of observations: 557697
201 number of observations: 536804
202 number of observations: 578269
203 number of observations: 544649
[helio@localhost temp]$ ./test
197 number of observations: 777980
198 number of observations: 764587
199 number of observations: 770005
200 number of observations: 623716
201 number of observations: 627000
202 number of observations: 630206
203 number of observations: 634468
[helio@localhost temp]$ ./test
197 number of observations: 695839
198 number of observations: 678020
199 number of observations: 681358
200 number of observations: 534876
201 number of observations: 537547
202 number of observations: 539711
203 number of observations: 543831
[helio@localhost temp]$ ./test
197 number of observations: 709759
198 number of observations: 684160
199 number of observations: 685812
200 number of observations: 534485
201 number of observations: 537334
202 number of observations: 573589
203 number of observations: 543497
On OpenSUSE 13.1 x64 2 core
helio@linux-techno:~> ./test
197 number of observations: 1060657
198 number of observations: 1097359
199 number of observations: 1104009
200 number of observations: 867470
201 number of observations: 872487
202 number of observations: 874292
203 number of observations: 881876
helio@linux-techno:~> ./test
197 number of observations: 730982
198 number of observations: 732811
199 number of observations: 736721
200 number of observations: 579397
201 number of observations: 584108
202 number of observations: 584735
203 number of observations: 588359
helio@linux-techno:~> ./test
197 number of observations: 731426
198 number of observations: 738590
199 number of observations: 741741
200 number of observations: 583523
201 number of observations: 584833
202 number of observations: 588973
203 number of observations: 592129
helio@linux-techno:~> ./test
197 number of observations: 730169
198 number of observations: 732672
199 number of observations: 737452
200 number of observations: 579829
201 number of observations: 583927
202 number of observations: 584652
203 number of observations: 589383
As you can see the time-jump also happens here. Note the high 1st run
times on OpenSUSE.
On Tue, Apr 15, 2014 at 4:49 PM, GOO Creations <goocreations(a)gmail.com
<mailto:goocreations@gmail.com>> wrote:
...
I've attached a small example program (with a makefile) that does
the test. I'm using gettimeofday, which will probably only work
under Linux. It might take a couple of seconds to execute. I would
apprciate it if someone could run it (sorry Allin, this is
probably the wrong mailing list again for posting C code), and
verify that I'm not the only one with this time-jump.
These are my outputs:
/197 number of observations: 784814//
//198 number of observations: 760379//
//199 number of observations: 759822//
//200 number of observations: 598327//
//201 number of observations: 602174//
//202 number of observations: 604390//
//203 number of observations: 607213//
/
Chris
_______________________________________________
Gretl-users mailing list
Gretl-users(a)lists.wfu.edu
http://lists.wfu.edu/mailman/listinfo/gretl-users
11:13 a.m.
On Wed, 16 Apr 2014, GOO Creations wrote:
Thanks Helio. So it's not just me.
Since the mathematics behind Mahalanobis indicate a linear dependency between
the observation count and the execution time, I'm simply going to ignore this
time-jump.
I've found the cause of the time-jump. It has nothing to do with the
actual Mahalanobis calculations and is purely to do with the apparatus for
printing the results, which up till now has been interleaved with the
computation (but is now separated in CVS).
The point is that we do certain calculations designed to ensure a
reasonably "pretty" printout, but once the sample size exceeds a certain
size we switch to a less rigorous but cheaper variant of that code. Since
your test program passes a NULL pointer for the printing there's actually
no call to run any of the prettification code, and in CVS we no longer do
so.
Allin Cottrell
11:30 a.m.
Confirmed! Allin is the best!!!
[helio@localhost temp]$ ./test
197 number of observations: 62789
198 number of observations: 52313
199 number of observations: 50733
200 number of observations: 50762
201 number of observations: 51009
202 number of observations: 50944
203 number of observations: 51234
[helio@localhost temp]$ ./test
197 number of observations: 63529
198 number of observations: 51731
199 number of observations: 49764
200 number of observations: 49832
201 number of observations: 50216
202 number of observations: 51201
203 number of observations: 50682
On Wed, Apr 16, 2014 at 12:13 PM, Allin Cottrell <cottrell(a)wfu.edu> wrote:
On Wed, 16 Apr 2014, GOO Creations wrote:
> Thanks Helio. So it's not just me.
>
> Since the mathematics behind Mahalanobis indicate a linear dependency
between
> the observation count and the execution time, I'm simply going to ignore
this
> time-jump.
I've found the cause of the time-jump. It has nothing to do with the
actual Mahalanobis calculations and is purely to do with the apparatus for
printing the results, which up till now has been interleaved with the
computation (but is now separated in CVS).
The point is that we do certain calculations designed to ensure a
reasonably "pretty" printout, but once the sample size exceeds a certain
size we switch to a less rigorous but cheaper variant of that code. Since
your test program passes a NULL pointer for the printing there's actually
no call to run any of the prettification code, and in CVS we no longer do
so.
Allin Cottrell
_______________________________________________
Gretl-users mailing list
Gretl-users(a)lists.wfu.edu
http://lists.wfu.edu/mailman/listinfo/gretl-users
12:26 p.m.
Hi,
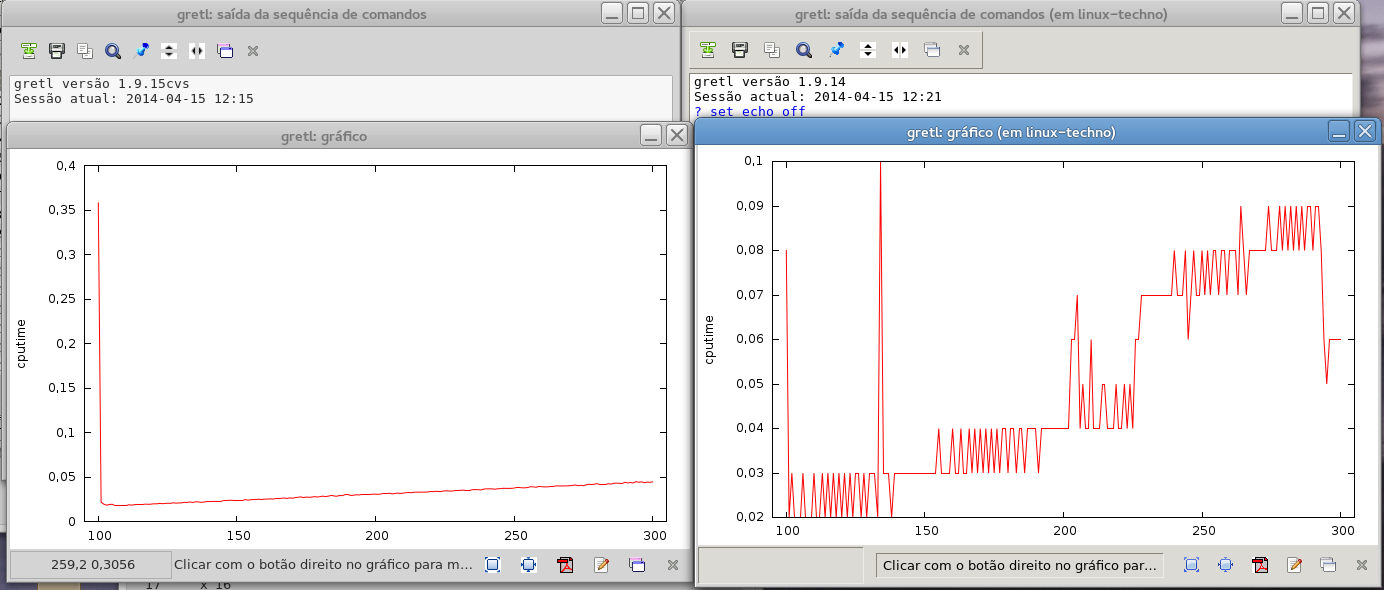
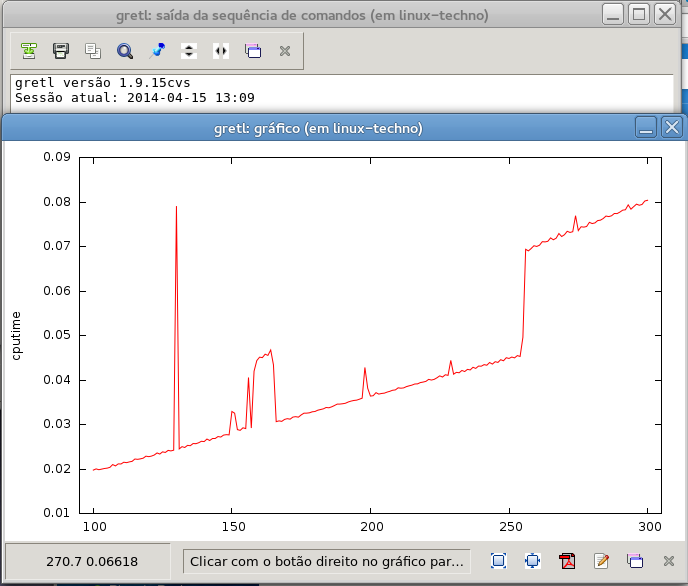
I tried Jack's script and found a curious different performances for a 2
core processor when compared with a 4 core processor (and different
builds). (The tests were not done in the same conditions, in Fedora there
was a logged in user in GUI, in OpenSUSE only with ssh)
Attached is a screenshot of the results. The systems are (both with 4GB
RAM):
On the left, Fedora Core 19 x64, Intel Core I5 2.5GHz (4 processors), gretl
CVS 1.9.15
On the right OpenSUSE 13.1 x64, Intel Core 2 Duo 3GHz, gretl 1.9.14
On the other screenshot we have same OpenSUSE 13.1, gretl CVS 1.9.15
Also attached the config log results.
Chart Observation:
Fedora, 1.9.15cvs: peek 0.35 range 0 - 0.05
OpenSUSE, 1.9.15cvs: peek 0.08 range 0.02 - 0.08
OpenSUSE, 1.9.14: peek 0.10 range 0.02 - 0.09
It would be interesting if we have a stable benchmark script (I can even
have it automated).
Hélio
{kind=link}
{kind=link}
4359
days inactive
4360
days old
12 comments
4 participants
participants (4)
-
 Allin Cottrell
Allin Cottrell -
 GOO Creations
GOO Creations -
 Hélio Guilherme
Hélio Guilherme -
 Riccardo (Jack) Lucchetti
Riccardo (Jack) Lucchetti